Data
The data that we use comes from German-language speeches of the Swiss parliament (Bundesversammlung). It was chosen because
- the source data is open to the public and allows for free distribution with the annotations
- the text allows for annotation of multiple sources and targets
- the text meets the research interests of several IGGSA-members, i.e. supports collaborations with political scientists and researches in digital humanities.
In selecting the data we took steps to minimize, or at least, mark any Swiss German idiosyncrasies. The selected speeches cover several different topics (foreign policy, book price controls, …) so as to give better coverage of the variety of ways in which sources and targets might be expressed.
The training data is now available for download. Note: because we found some minor technical errors in the xml file, we provide a corrected version (July 29, 2016).
We also provide a preprocessed version of this data.
The test data for the shared task is now also available for download.
We provide two files. In the file for the full task, no gold information is provided.
In the file for the subtasks, we have pre-identified the subjective expressions.
We also provide a preprocessed version of this data.
Now that the task has run the gold data for the shared task is available for download.
Annotations
Matching the general task we try to solve, the annotation scheme consists of three major types of labels: Sources, Targets, and SubjectiveExpressions. These are inter-related by way of annotation frames that are centered on the Subjective Expressions. In addition, the three label types allow for several kinds of additional markings (flags), which indicate additional attributes of the labels.
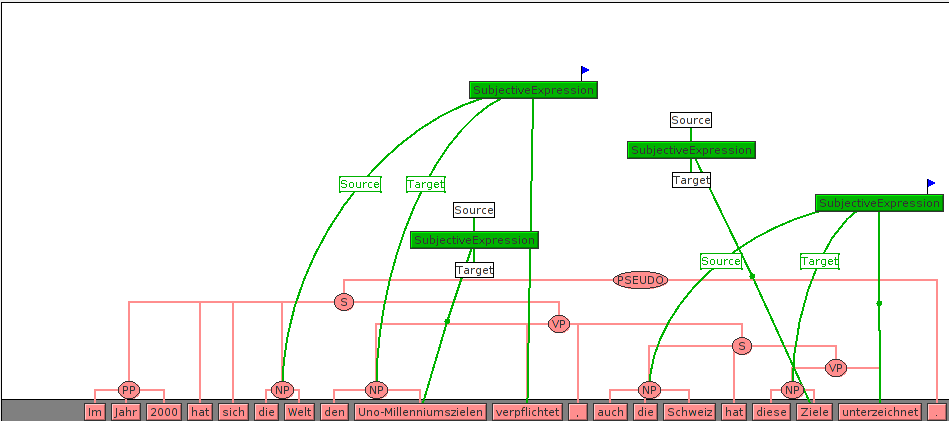
The annotations represent an adjudicated version of the 2014 test data. The guidelines can be downloaded here.
Note that participating groups can use additional suitable training data as well as any kind of additional tools such as parsers etc. to develop their own systems.
Subtasks and Evaluation
We offer three subtasks:
* Full task Identification of subjective expressions with their respective sources and targets
* Subtask a) Participants are given the subjective expressions and are only asked to identify opinion sources.
* Subtask b) Participants are given the subjective expressions and are only asked to identify opinion targets.
Scorer
The evaluation tool for the Shared Task is available for download as a Java runnable jar file.
Documentation for the tool is provided here.
Formats
The STEPS data set has undergone the following pre-processing: sentence segmentation and tokenization using OpenNLP, lemmatization with the TreeTagger (Schmid, 1994), constituency parsing using the Berkeley parser (Petrov and Klein, 2007), and conversion of the parse trees into TigerXML-Format using TIGER-tools (Lezius, 2002). For the annotation we used the Salto-Tool (Burchardt et al. 2006). The existing Salsa API can be used for XML-files in this format.
For your convenience, all data from this Maintask has been preprocessed with tokenisation, part-of-speech tagging and syntactic analysis! But participants are of course free to do their own pre-processing.
Schedule
| March | Call for Participation | |
| Start of April | Release of training data | |
| July 29 | Registration deadline | |
| August, 1st | Release of test data | |
| August, 15th | System runs submitted | |
| August,31st | Notification of results | |
| Middle of September | Drafts of workshop papers due | |
| September 22 | Workshop @ KONVENS 2016 in Bochum | |
| End of October | Publication of final workshop papers |
Acknowledgment
We are happy to acknowledge the finanical support that the GSCL (German Society for Computational Linguistics) has granted us for the annotation of the training data.